什么是JDBC?
Java语言访问数据库的一种规范,是一套API
JDBC (Java Database Connectivity) API,即Java数据库编程接口,是一组标准的Java语言中的接口和类,使用这些接口和类,Java客户端程序可以访问各种不同类型的数据库。比如建立数据库连接、执行SQL语句进行数据的存取操作。
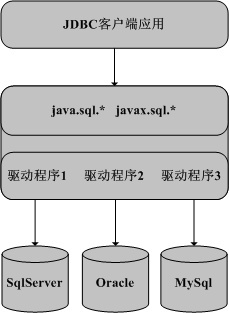
JDBC规范采用接口和实现分离的思想设计了Java数据库编程的框架。接口包含在java.sql及javax.sql包中,其中java.sql属于JavaSE,javax.sql属于JavaEE。这些接口的实现类叫做数据库驱动程序,由数据库的厂商或其它的厂商或个人提供。
为了使客户端程序独立于特定的数据库驱动程序,JDBC规范建议开发者使用基于接口的编程方式,即尽量使应用仅依赖java.sql及javax.sql中的接口和类。
JDBC驱动程序:
什么是JDBC驱动程序?
这些是各个数据库厂家根据JDBC的规范制作的JDBC实现类
JDBC驱动程序的四种类型:
1. 第一种类型的驱动程序的实现是通过将JDBC的调用全部委托给其它编程接口来实现的,比如ODBC。这种类型的驱动程序需要安装本地代码库,即依赖于本地的程序,所以便携性较差。比如JDBC-ODBC桥驱动程序
2. 第二种类型的驱动程序的实现是部分基于Java语言的。即该驱动程序一部分是用Java语言编写,其它部分委托本地的数据库的客户端代码来实现。同类型1的驱动一样,该类型的驱动程序也依赖本地的程序,所以便携性较差
3. 第三种类型的驱动程序的实现是全部基于JAVA语言的。该类型的驱动程序通常由某个中间件服务器提供,这样客户端程序可以使用数据库无关的协议和中间件服务器进行通信,中间件服务器再将客户端的JDBC调用转发给数据库进行处理
4. 第四种类型的驱动程序的实现是全部基于JAVA语言的。该类型的驱动程序中包含了特定数据库的访问协议,使得客户端可以直接和数据库进行通信
JDBC类结构:
DriverManager
Driver Driver
Connection Connection
Statement Statement
Resultset Resultset
DriverManager:这个是一个实现类,它是一个工厂类,用来生产Driver对象的
这个类的结构设计模式为工厂方法
Driver:这是驱动程序对象的接口,它指向一个实实在在的数据库驱动程序对象,那么这个数据库驱动程序对象是从哪里来的呢?
DriverManager工厂中有个方法:getDriver(String URL),通过这个方法可以得到驱动程序对象,这个方法是在各个数据库厂商按JDBC规范设计的数据库驱动程序包里的类中静态实现的,也就是在静态块中
Connection:这个接口可以制向一个数据库连接对象,那么如何得到这个连接对象呢?
是通过DriverManager工厂中的getConnection(String URL)方法得到的
Statement:用于执行静态的SQL语句的接口,通过Connection中的createStatement方法得到的
Resultset:用于指向结果集对象的接口,结果集对象是通过Statement中的execute等方法得到的
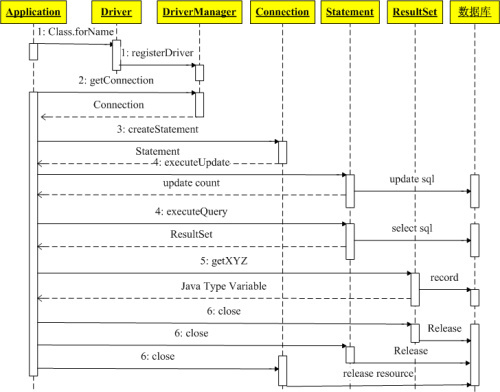
JAVA使用JDBC访问数据库的步骤:
1. 得到数据库驱动程序
2. 创建数据库连接
3. 执行SQL语句
4. 得到结果集
5. 对结果集做相应的处理(增,删,改,查)
6. 关闭资源:这里释放的是DB中的资源
设置classpath:
1. 在java文件中起的包名一定要是工程基目录下的子目录,classpath:基目录
2. .jar包,需要将这个.jar包的路径包括这个文件的全名添加到classpath中来
Oracle连接字符串的书写格式:
“oracle:jdbc:thin:@ip:1521: 数据库名”,”数据库用户名”,”数据库密码”
简单的例子:
package moudule1.first;
import java.sql.*;
public class FirstJdbc
{ public static void main(String[] args){ String sql="select * from yuchen_user"; Connection con=null; Statement st=null; ResultSet rs=null; try{ Class.forName("oracle.jdbc.driver.OracleDriver"); con=DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:name", "scott","tiger"); st=con.createStatement(); rs=st.executeQuery(sql); while(rs.next()){ System.out.println(rs.getInt("id")); System.out.println(rs.getString("name")); } }catch(Exception e){ e.printStackTrace(); }finally{ con.close(); }
}
}
=================================================================================
一.代码的可读性和. 虽然用PreparedStatement来代替Statement会使代码多出几行,但这样的代码无论从可读性还是上来说.都比直接用Statement的代码高很多档次: stmt.executeUpdate("insert into tb_name (col1,col2,col2,col4) values ('"+var1+"','"+var2+"',"+var3+",'"+var4+"')"); perstmt = con.prepareStatement("insert into tb_name (col1,col2,col2,col4) values (?,?,?,?)"); perstmt.setString(1,var1); perstmt.setString(2,var2); perstmt.setString(3,var3); perstmt.setString(4,var4); perstmt.executeUpdate(); 不用我多说,对于第一种方法.别说其他人去读你的代码,就是你自己过一段时间再去读,都会觉得伤心. 二.PreparedStatement尽最大可能提高性能. 每一种数据库都会尽最大努力对语句提供最大的.因为语句有可能被重用.所以语句在被DB的编译后的执行代码被缓存下来,那么下次调用时只要是相同的语句就不需要编译,只要将参数直接传入编译过的语句执行代码中(相当于一个涵数)就会得到执行.这并不是说只有一个Connection中多次执行的预编译语句被缓存,而是对于整个DB中,只要预编译的语句语法和缓存中匹配.那么在任何时候就可以不需要再次编译而可以直接执行.而statement的语句中,即使是相同一操作,而由于每次操作的数据不同所以使整个语句相匹配的机会极小,几乎不太可能匹配.比如: insert into tb_name (col1,col2) values ('11','22'); insert into tb_name (col1,col2) values ('11','23'); 即使是相同操作但因为数据内容不一样,所以整个个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存.这样每执行一次都要对传入的语句编译一次. 当然并不是所以预编译语句都一定会被缓存,数据库本身会用一种策略,比如使用频度等因素来决定什么时候不再缓存已有的预编译结果.以保存有更多的空间存储新的预编译语句. 三.最重要的一点是极大地提高了安全性. 即使到目前为止,仍有一些人连基本的恶义SQL语法都不知道. String sql = "select * from tb_name where name= '"+varname+"' and ='"+var+"'"; 如果我们把[' or '1' = '1]作为var传入进来.用户名随意,看看会成为什么? select * from tb_name = '随意' and passwd = '' or '1' = '1'; 因为'1'='1'肯定成立,所以可以任何通过验证.更有甚者: 把[';drop table tb_name;]作为varpasswd传入进来,则: select * from tb_name = '随意' and passwd = '';drop table tb_name;有些数据库是不会让你成功的,但也有很多数据库就可以使这些语句得到执行. 而如果你使用预编译语句.你传入的任何内容就不会和原来的语句发生任何匹配的关系.(前提是数据库本身支持预编译,但上前可能没有什么数据库不支持编译了,只有少数的桌面数据库,就是直接文件访问的那些)只要全使用预编译语句,你就用不着对传入的数据做任何过虑.而如果使用普通的statement,有可能要对drop,;等做费尽心机的判断和过虑 pasting